Filename Encoding and Decoding¶
The filename encoding and decoding is on one hand designed based on special characters representing a token for the file name scanners and parsers, on the other hand it is targeting a flexible representation in human readable formats. Therefore in modern environments this makes use of multiple character sets and internaionalization. This in particular makes excessive use of the character and string encoding and decoding.
Basics of Encoding and Decoding¶
The encoding and decoding is commonly designed as a hierarchy for the conversion of bits into human readable symbols. The sub-processes are commonly designed as a stack of conversion routines where the bottom layer represents the machine language, and the top layer the written loacalized human language. The stack itself defines commonly the sublayers of the syntactic information units:
- String - groups of characters
- Multilingual Character - one or more bytes with special mapping onto complex human language characters, most popular Unicode
- Character - a byte with special mapping onto a human language character
- Byte - group of bits
- Bit
Python Encoding and Decoding Facilities¶
The encoding and decoding is one of the major changes from Python2 to Python3. This causes for the proting of several opensource projects larger impacts resulting in comprising coding efforts, even in thorougly and clean designs.
The following definitions apply:
- encoding Encrypt into the direction of machine language
- decoding Decrypt into the direction of human language
Python2¶
Python2 distinguishes basically the encoding stack into 5-encoding-layers.
- unicode - Strings a multi-character arrays
- str - Strings a single-character arrays
- raw - characters in arrays - ASCII / order
- bytes as int - bit groups
- bits - bits which may not, but could be used in general raw processing
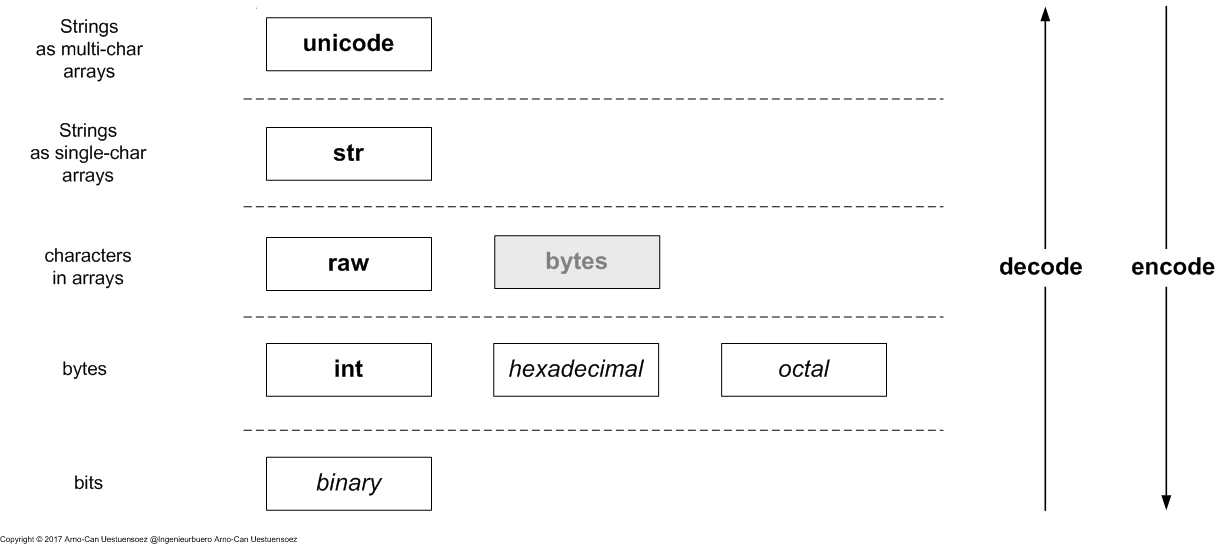
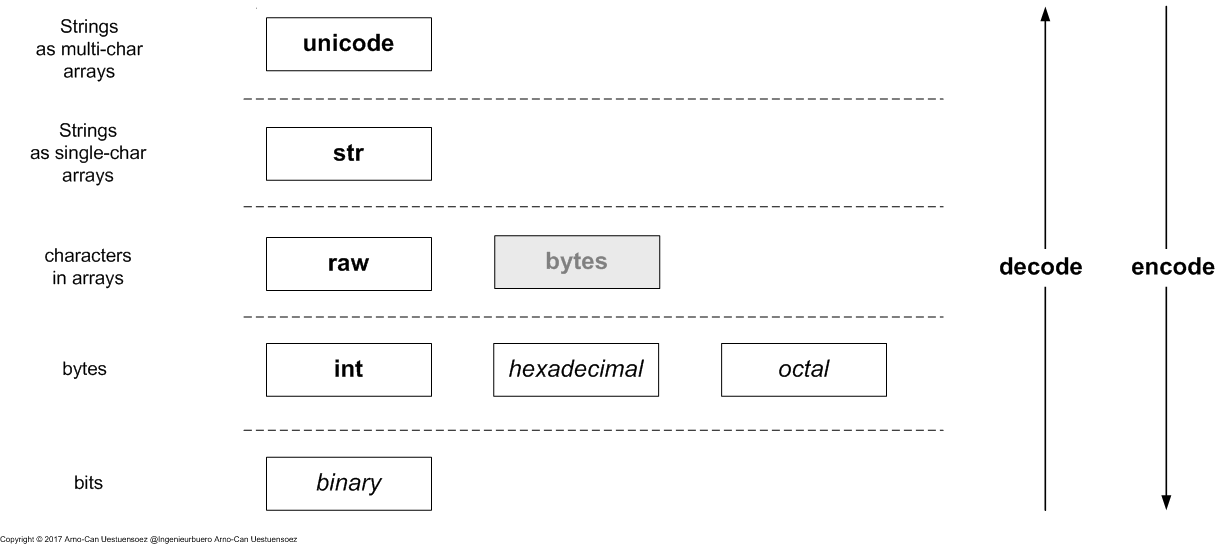
The special case is here bytes which represent a prepration for the migration to Python3, but neither has a real distinction to the Python2 str type, nor prerents a call compatible interface.
Thus it seems to be a general viable approach to prefer the encode() and decode() calls.
Python3¶
Python3 distinguishes basically the encoding stack into 4-encoding-layers.
- str - Strings a unicode character arrays, either one or more characters
- bytes - characters in arrays - ASCII / order
- bytes as int - bit groups
- bits - bits which may not, but could be used in general raw processing
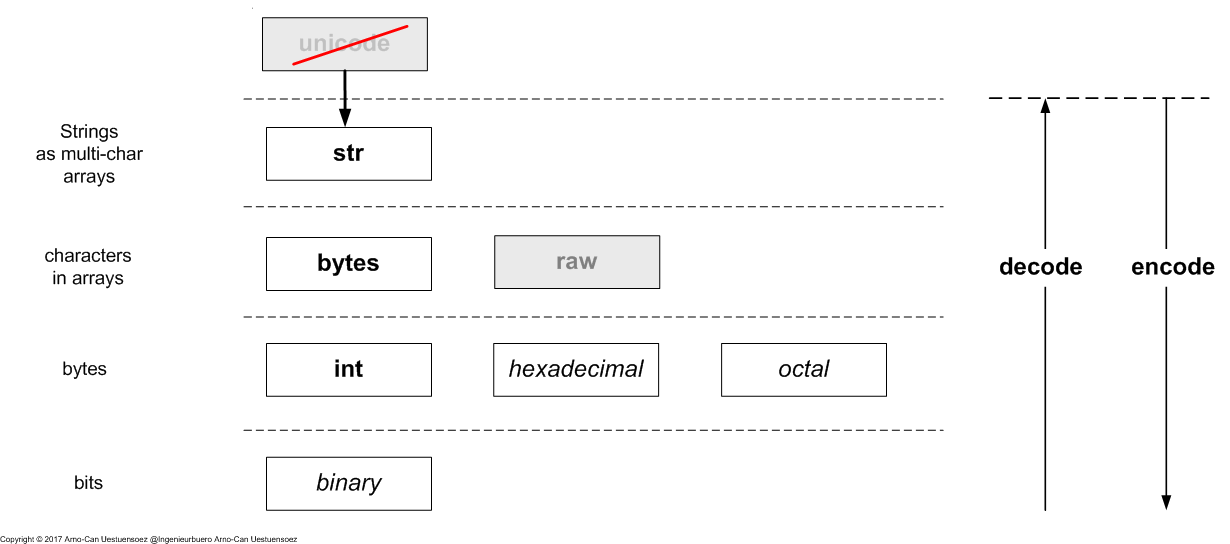
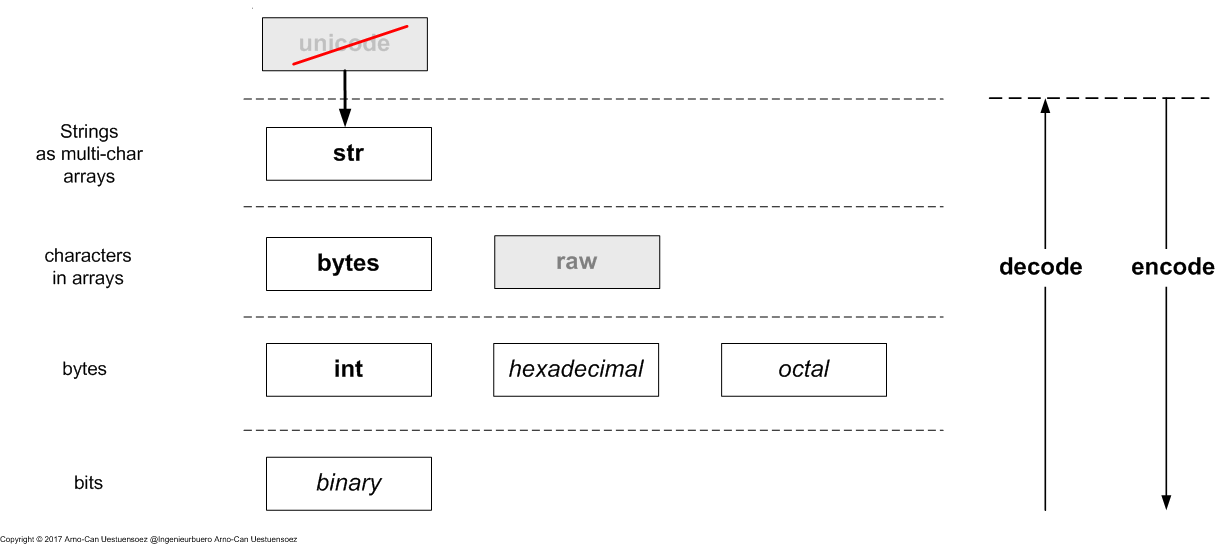
The unicode class is migrated into the str class. The raw string is replaced by the bytes class. This in particular leaves some Python2 calls non-compilable. Thus it seems to be a general viable approach to prefer the encode() and decode() calls in case of shared code with Python2.
Call Interfaces¶
The following major interfaces are provided for encoding and decoding.
| Python2 | Python3 | Remarks | |
|---|---|---|---|
| bytes => str | str(x), x.decode(‘ascii’) | x.decode(‘ascii’), x.decode(‘utf_8’) | 2:bytes==str |
| bytes => unicode | x.decode(‘utf_8’) | arg = str(arg_b,’utf_8’), x.decode(‘utf_8’) | 3: NOK: str(arg_b) -> str: b’\u0041\u0042/’ |
| raw => bytes | bytes(x) | bytes(x, ‘ascii’), x.encode(‘ascii’) | 2:bytes==str, 3:bytes==raw-str |
| raw => str | str(x) | str(x), x.decode(‘utf_8’) | 2:bytes==str, 3:bytes==raw-str |
| raw => unicode | unicode(x) | str(x), x.decode(‘utf_8’) | 2:bytes==str, 3:bytes==raw-str |
| str => bytes | x.encode(‘ascii’) | bytes(x, ‘ascii’), x.encode(‘ascii’) | 2:bytes==str |
| str => raw | x.encode(‘ascii’) | bytes(x, ‘ascii’), x.encode(‘ascii’) | 3:bytes==raw-str |
| str => unicode | unicode(x), x.decode(‘utf_8’) | – | 3: str == unicode |
| unicode => bytes | x.encode(‘ascii’) | x.encode(‘ascii’), bytes(‘ascii’) | |
| unicode => str | x.encode(‘ascii’) | – | 3: str == unicode |
See [codecsStandard] for standard codecs.
Special Remarks:
bytes => str - Python2
Because bytes is a str, the x.decode(‘ascii’) call results in unitype.
Supported Encodings¶
The filesysobjects supports as input and ouput str, raw-str and unicode. The str and unicode are in Python3 the same, while in Python2 these are different types. The type bytes has to be converted into an str for Python3, while it is the same type as str, thus could not be distinguished.
| Input | API | Output | Remarks | |
|---|---|---|---|---|
| Python2 | Python3 | |||
| str | str | str | str(unicode) | 3: unicode == str |
| raw | raw | str | str(unicode) | raw str |
| unicode | unicode/str | str | str(unicode) | 3: unicode == str |
The limit is given here by the internal re based scanners and parsers. The input type is kept for the output values, or choosen as close to the original as possible.
