A Primer on File and Directory Resources¶
The package ‘filesysobjects’ supports the hierarchical navigation based on resource paths, with special support of file system based resources.
Common Path Addresses¶
The syntax elements for the normalization of pathnames are in particular essential for the treatment of the filesystem structure as a class and object hierarchy. Thus the behaviour has to be defined thoroughly from the beginning, even or better in particular in case of the foreseen evolutionary add-on extension.
The current release provides the following syntax, successive compatible extensions are going to follow soon. These the processing of the provided syntax is designed in two layers in accordance to common examples.
The lower layer provides the syntax elements to construct a pathname for local access, whereas the upper layer provides the information for the location of remote filesystems.
The following figure draftly weights the degree of exchangability and inter operability of the supported name-binding by the resource file path specifications. Where the darkness of the grey background symbolizes a tighter overall coupling.
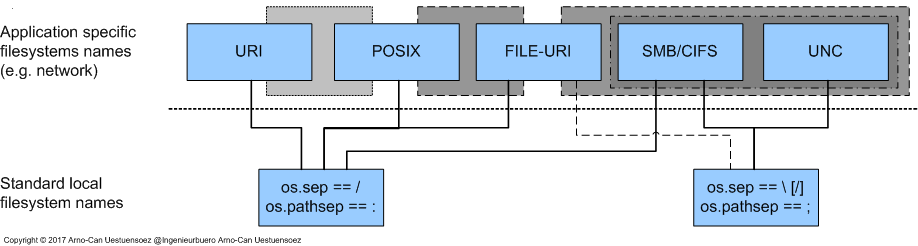
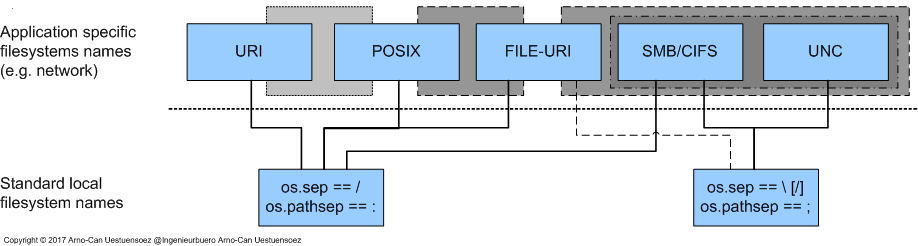
Filesystem Paths¶
The following sections sums up and documents the required file and directory address standards and conventions. The intention is hereby to provide a quick access to the extracted relevant parts of the considerable amount of documents.
Cygwin¶
Cygwin is a Unix environment on MS-Windows. It is less a filesystem, but provides the filesystem of the hosting Windows OS, and in addition addressing by Posix compliant file path names. The provided libraries distinguish hereby an additional ‘mixed-mode’, which adds a Posix compliant pathname to a conventional drive letter.
The current release of filesysobjects provides not support for the special handling of the Cygwin conventions. Cygwin as runtime environment is fully supported.
FAT¶
File allocation table (FAT) [FAT] .
See also
File allocation table (FAT) [FAT]
FAT Root Folder Structure
| Root Folder Entry | Size | Description |
|---|---|---|
| Name | 11 bytes | Name in 8.3 format. |
See also
File allocation table (FAT) [FAT]
File Naming
Windows Server 2003 supports both long and short file names on FAT volumes.
File Names on FAT Volumes
Files created or renamed on FAT volumes use attribute bits to support long file names in a way that does not interfere with how MS-DOS gains access to the volume.
When you create a file that has a long file name, Windows Server 2003 creates a conventional 8.3 name for the file and one or more secondary folder entries for the file, one for each set of 13 characters in the long file name. Each secondary folder entry stores a corresponding part of the long file name in Unicode. MS-DOS accesses the file by using the conventional 8.3 file name contained in the folder entry for the file.
Windows Server 2003 marks the secondary folder entries as part of a long file name by setting the volume ID, read-only, system, and hidden attribute bits. MS-DOS typically ignores folder entries with all these attribute bits set.
The following figure shows all of the folder entries for the file Thequi~1.fox, which has a long name, “The quick brown.fox.” The long name is in Unicode and each character in the name uses 2 bytes in the folder entry. The attribute field for the long-name entries has the value 0x0F. The attribute field for the short name has the value 0x20.
Long File Name on a FAT Volume
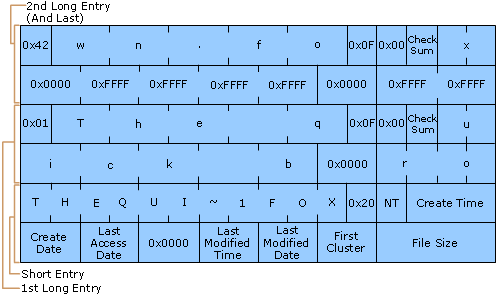
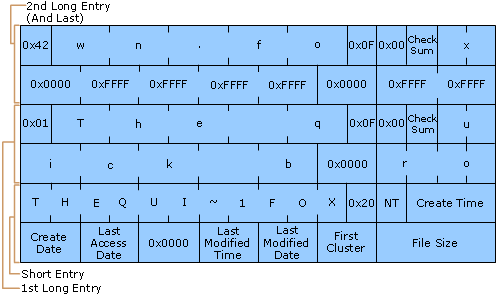
Note
Windows NT and Windows Server 2003 do not use the same algorithm to create long and short file names as Windows 95, Windows 98, and Windows Me. However, on computers that use a multiple-boot configuration to start these operating systems, files that you create while running one operating system can be accessed while running another.
By default, Windows Server 2003 supports long file names on FAT volumes. You can disable long file names on FAT volumes if you use MS-DOS–based disk tools regularly on the computer. These tools might either eliminate the long file names created by Windows Server 2003 or delete the files that have long file names.
Note
It is advised that you do not disable long file names on FAT volumes.
How Windows Server 2003 Creates File Names
File names in Windows Server 2003 can be up to 255 characters and can contain spaces, multiple periods, and special characters that are not allowed in MS-DOS file names. Windows Server 2003 makes it possible for other operating systems to access files that have long names by generating an MS-DOS-readable (8.3) name for each file. These MS-DOS-readable names also enable MS-DOS-based and Windows 3.x–based applications to recognize and load files that have long file names. When a program saves a file on a computer running Windows Server 2003, both the 8.3 file name and long file name are retained.
Note
The 8.3 format means that files can have between 1 and 8 characters in the file name. The name must start with a letter or a number and can contain any characters except the following:
. " / \ [ ] : ; | = , * ? (space)
An 8.3 file name typically has a file name extension that is from one to three characters long and has the same character restrictions. A period separates the file name from the file name extension.
Several special file names are reserved by the system and cannot be used for files or folders: CON, AUX, COM1, COM2, COM3, COM4, LPT1, LPT2, LPT3, PRN, and NUL.
When you create a file that has a long file name, Windows Server 2003 creates a conventional 8.3 name for the file and one or more secondary folder entries for the file, one for each set of 13 characters in the long file name. Each secondary folder entry stores a corresponding part of the long file name in Unicode. MS-DOS accesses the file by using the conventional 8.3 file name contained in the folder entry for the file.
Windows Server 2003 marks the secondary folder entries as part of a long file name by setting the volume ID, read-only, system, and hidden attribute bits. MS-DOS typically ignores folder entries with all these attribute bits set.
Generating Short File Names
In Windows Server 2003, FAT uses the Unicode character set, which contains several prohibited characters that MS-DOS cannot read, for their names. To generate a short MS-DOS-readable file name, Windows Server 2003 deletes all of these characters from the long file name and removes any spaces, but ensures that the generated short file name is unique. Because an MS-DOS-readable file name can have only one period, Windows Server 2003 also removes extra periods from the file name.
.
HFS/HFS+¶
The filesysobjects supports on OS-X the POSIX standard for local components of file system path names. The historic legacy with the colon ‘:’ as alias for the ‘/’ in finder [os.path] [macpath] is not supported by the filesysobjects.
See RFC8089 Appendix-D.3.
NTFS¶
Supports full scope.
See also
NTFS Technical Reference [NTFS]
How NTFS Works
Updated: March 28, 2003
NTFS File Attribute Types
| Attribute Type | Description |
|---|---|
File Name additional file name attributes. |
A repeatable attribute for both long and short file names. The long name of the file can be up to 255 Unicode characters. The short name is the 8.3, case-insensitive name for the file. Additional names, or hard links, required by POSIX can be included as |
See also
NTFS Technical Reference [NTFS]
File Naming
Windows Server 2003 supports both long and short file names on NTFS volumes. File Names in Windows Server 2003
Every time you create a file with a long file name, NTFS creates a second file entry that has a similar 8.3 short file name. A file with an 8.3 short file name has a file name containing 1 to 8 characters and a file name extension containing 1 to 3 characters. The file name and file name extension are separated by a period.
File names in Windows Server 2003 can be up to 255 characters and can contain spaces, multiple periods, and special characters that are not allowed in MS-DOS file names. Windows Server 2003 makes it possible for other operating systems to access files that have long names by generating an MS-DOS-readable (8.3) name for each file. These MS-DOS-readable names also enable MS-DOS-based and Windows 3.x–based applications to recognize and load files that have long file names. When a program saves a file on a computer running Windows Server 2003, both the 8.3 file name and long file name are retained.
Note
The 8.3 format means that files can have between 1 and 8 characters in the file name. The name must start with a letter or a number and can contain any characters except the following:
. " / \ [ ] : ; | = , * ? (space)
An 8.3 file name typically has a file name extension that is from one to three characters long and has the same character restrictions. A period separates the file name from the file name extension.
Several special file names are reserved by the system and cannot be used for files or folders: CON, AUX, COM1, COM2, COM3, COM4, LPT1, LPT2, LPT3, PRN, NUL
How NTFS Generates Short File Names
In Windows Server 2003, both FAT and NTFS use the Unicode character set, which contains several prohibited characters that MS-DOS cannot read, for their names. To generate a short MS-DOS-readable file name, Windows Server 2003 deletes all of these characters from the long file name and removes any spaces. Because an MS-DOS-readable file name can have only one period, Windows Server 2003 also removes extra periods from the file name. If necessary, Windows Server 2003 truncates the file name to six characters and appends a tilde (~) and a number. For example, each non-duplicate file name is appended with ~1. Duplicate file names end with ~2, then ~3, and so on. After the file names are truncated, the file name extensions are truncated to three or fewer characters. Finally, when displaying file names at the command line, Windows Server 2003 translates all characters in the file name and extension to uppercase.
Note
You can permit extended characters by using the fsutil behavior set command. You must restart the computer before this setting takes effect. For more information about using the fsutil behavior set command, see the topic Fsutil: behavior in Help and Support Center in Windows Server 2003.
When five or more files exist that can result in duplicate short file names, Windows Server 2003 uses a slightly different method for creating short file names. For the fifth and subsequent files, Windows Server 2003:
Uses only the first two letters of the long file name.
Generates the next four letters of the short file name by mathematically manipulating the remaining letters of the long file name.
Appends ~1 (or another number, if necessary, to avoid a duplicate file name) to the result.
This method substantially improves performance when Windows Server 2003 must create short file names for a large number of files with similar long file names. Windows Server 2003 uses this method to create short names for files on both FAT and NTFS volumes.
The following table shows the short file names for files created by six tests.
Short File Names Created by Windows Server 2003 — Example One
| Long File Name | Short File Name |
|---|---|
| This is test 1.txt | THISIS~1.TXT |
| This is test 2.txt | THISIS~2.TXT |
| This is test 3.txt | THISIS~3.TXT |
| This is test 4.txt | THISIS~4.TXT |
| This is test 5.txt | THA1CA~1.TXT |
| This is test 6.txt | THA1CE~1.TXT |
If the long file names in the preceding table are created in a different order, their short file names are different, as shown in the following table.
Short File Names Created by Windows Server 2003 — Example Two
| Long File Name | Short File Name |
|---|---|
| This is test 2.txt | THISIS~1.TXT |
| This is test 3.txt | THISIS~2.TXT |
| This is test 1.txt | THISIS~3.TXT |
| This is test 4.txt | THISIS~4.TXT |
| This is test 5.txt | THA1CA~1.TXT |
| This is test 6.txt | THA1CE~1.TXT |
When you delete a file, its short file name is also deleted. When you create new files in the same folder, Windows Server 2003 might re-use short file names that have been deleted. For instance, in Example 1, if you delete the file “This is test 1.txt,” and then create a new file called “This is test 7.txt,” its short file name becomes THISIS~1.TXT.
If you have a large number of files (300,000 or more) in a folder, and the files have long file names with the same initial characters, the time required to create the files increases. The increase occurs because NTFS bases the short file name on the first six characters of the long file name. In folders with more than 300,000 files, the short file names start to conflict after NTFS uses all of the 8.3 names that are similar to the long file names. Repeated conflicts between a generated short file name and existing short file names cause NTFS to regenerate the short file name from 6 to 8 times.
For Posix compatibility:
See also
NTFS Technical Reference [NTFS]
POSIX Compliance
NTFS provides a several features to support the Portable Operating System Interface (POSIX) standard, which is defined by the Institute of Electrical and Electronic Engineers (IEEE) standard 1003.1-1990 (also known as ISO/IEC 9945-1:1990).
NTFS includes the following POSIX-compliant features.
- Case-sensitive naming
- For example, POSIX interprets README.TXT, Readme.txt, and readme.txt as separate files.
- Hard links
- A file can have more than one name. This allows two different file names, which can be in different folders on the same volume, to point to the same data.
- Additional time stamps
- These show when the file was last accessed or modified.
The POSIX subsystem included with Windows NT and Windows 2000 is not included with Windows Server 2003. A new subsystem supporting the broad functionality found on most UNIX systems beyond the POSIX.1 standard is shipped as part of Interix 2.2. The Interix subsystem can be certified to the NIST FIPS 151-2 POSIX Conformance Test Suite.
- Note You must use Interix-based programs to manage file names that
- differ only in case. You cannot use standard Windows Server 2003 command-line tools (such as copy, del, and move, or their equivalents in Windows Explorer or My Computer) to manage file names that differ only in case.
Posix - IEEE-1003¶
The filesys objects provides the full scope of the file and path names syntax as defined by the IEEE-1003.1 - 2013 [IEEE1003] . This is the base for the supported file system addresses by filesysobjects on Linux, BSD, Unix, and OS-X.
The specification includes ordinary local file and pathnames with an optional application prefix defined by double-slashes, similar to the leading double backslashes of a UNC.
See also
IEEE-1003.1 - 2013 [IEEE1003]
3.267 Pathname
A string that is used to identify a file. In the context of POSIX.1-2008, a pathname may be limited to {PATH_MAX} bytes, including the terminating null byte. It has optional beginning <slash> characters, followed by zero or more filenames separated by <slash> characters. A pathname can optionally contain one or more trailing <slash> characters. Multiple successive <slash> characters are considered to be the same as one <slash>, except for the case of exactly two leading <slash> characters.
- Note:
If a pathname consists of only bytes corresponding to characters from the portable filename character set (see Portable Filename Character Set), <slash> characters, and a single terminating <NUL> character, the pathname will be usable as a character string in all supported locales; otherwise, the pathname might only be a string (rather than a character string). Additionally, since the single-byte encoding of the <slash> character is required to be the same across all locales and to not occur within a multi-byte character, references to a <slash> character within a pathname are well-defined even when the pathname is not a character string. However, this property does not necessarily hold for the remaining characters within the portable filename character set.
Pathname Resolution is defined in detail in Pathname Resolution.
The filename either names a directory component of a pathname, or literally a file.
See also
IEEE-1003.1 - 2013 [IEEE1003]
3.170 Filename
A sequence of bytes consisting of 1 to {NAME_MAX} bytes used to name a file. The bytes composing the name shall not contain the <NUL> or <slash> characters. In the context of a pathname, each filename shall be followed by a <slash> or a <NUL> character; elsewhere, a filename followed by a <NUL> character forms a string (but not necessarily a character string). The filenames dot and dot-dot have special meaning. A filename is sometimes referred to as a “pathname component”. See also Pathname.
- Note:
- Pathname Resolution is defined in detail in Pathname Resolution .
3.171 Filename String
A string consisting of a filename followed by a <NUL> character.
Modern filesystems accept unicode characters, the Posix specification defines a portablle character set, which is mandatorily available on each conformant system, including e.g. embedded devices.
See also
IEEE-1003.1 - 2013 [IEEE1003]
3.278 Portable Filename Character Set
The set of characters from which portable filenames are constructed.
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
a b c d e f g h i j k l m n o p q r s t u v w x y z
0 1 2 3 4 5 6 7 8 9 . _ -
The last three characters are the <period>, <underscore>, and <hyphen> characters, respectively. See also Pathname.
For the pathname resolution.
See also
IEEE-1003.1 - 2013 [IEEE1003]
4.12 Pathname Resolution
Pathname resolution is performed for a process to resolve a pathname to a particular directory entry for a file in the file hierarchy. There may be multiple pathnames that resolve to the same directory entry, and multiple directory entries for the same file. When a process resolves a pathname of an existing directory entry, the entire pathname shall be resolved as described below. When a process resolves a pathname of a directory entry that is to be created immediately after the pathname is resolved, pathname resolution terminates when all components of the path prefix of the last component have been resolved. It is then the responsibility of the process to create the final component.
Each filename in the pathname is located in the directory specified by its predecessor (for example, in the pathname fragment a/b, file b is located in directory a). Pathname resolution shall fail if this cannot be accomplished. If the pathname begins with a <slash>, the predecessor of the first filename in the pathname shall be taken to be the root directory of the process (such pathnames are referred to as “absolute pathnames”). If the pathname does not begin with a <slash>, the predecessor of the first filename of the pathname shall be taken to be either the current working directory of the process or for certain interfaces the directory identified by a file descriptor passed to the interface (such pathnames are referred to as “relative pathnames”).
The interpretation of a pathname component is dependent on the value of {NAME_MAX} and _POSIX_NO_TRUNC associated with the path prefix of that component. If any pathname component is longer than {NAME_MAX}, the implementation shall consider this an error.
A pathname that contains at least one non- <slash> character and that ends with one or more trailing <slash> characters shall not be resolved successfully unless the last pathname component before the trailing <slash> characters names an existing directory or a directory entry that is to be created for a directory immediately after the pathname is resolved. Interfaces using pathname resolution may specify additional constraints1 when a pathname that does not name an existing directory contains at least one non- <slash> character and contains one or more trailing <slash> characters.
If a symbolic link is encountered during pathname resolution, the behavior shall depend on whether the pathname component is at the end of the pathname and on the function being performed. If all of the following are true, then pathname resolution is complete:
This is the last pathname component of the pathname.
The pathname has no trailing <slash>.
The function is required to act on the symbolic link itself, or certain arguments direct that the function act on the symbolic link itself.
In all other cases, the system shall prefix the remaining pathname, if any, with the contents of the symbolic link. If the combined length exceeds {PATH_MAX}, and the implementation considers this to be an error, errno shall be set to [ENAMETOOLONG] and an error indication shall be returned. Otherwise, the resolved pathname shall be the resolution of the pathname just created. If the resulting pathname does not begin with a <slash>, the predecessor of the first filename of the pathname is taken to be the directory containing the symbolic link.
If the system detects a loop in the pathname resolution process, it shall set errno to [ELOOP] and return an error indication. The same may happen if during the resolution process more symbolic links were followed than the implementation allows. This implementation-defined limit shall not be smaller than {SYMLOOP_MAX}.
The special filename dot shall refer to the directory specified by its predecessor. The special filename dot-dot shall refer to the parent directory of its predecessor directory. As a special case, in the root directory, dot-dot may refer to the root directory itself.
A pathname consisting of a single <slash> shall resolve to the root directory of the process. A null pathname shall not be successfully resolved. If a pathname begins with two successive <slash> characters, the first component following the leading <slash> characters may be interpreted in an implementation-defined manner, although more than two leading <slash> characters shall be treated as a single <slash> character.
Pathname resolution for a given pathname shall yield the same results when used by any interface in POSIX.1-2008 as long as there are no changes to any files evaluated during pathname resolution for the given pathname between resolutions.
The filesysobjects support RFC8089 Appendix-D.1.
UNC¶
The Universal Naming Convention (UNC) [MS-DTYP] is implemented by the following syntax.
See also
Universal Naming Convention (UNC) [MS-DTYP]
UNC = "\\" host-name "\" share-name [ "\" object-name ]
host-name = "[" IPv6address ‘]" / IPv4address / reg-name
; IPv6address, IPv4address, and reg-name as specified in [RFC3986]_
share-name = 1*80pchar
pchar = %x20-21 / %x23-29 / %x2D-2E / %x30-39 / %x40-5A / %x5E-7B / %x7D-FF
object-name = *path-name [ "\" file-name ]
path-name = 1*255pchar
file-name = 1*255fchar [ ":" stream-name [ ":" stream-type ] ]
fchar = %x20-21 / %x23-29 / %x2B-2E / %x30-39 / %x3B / %x3D / %x40-5B / %x5D-7B
/ %x7D-FF
stream-name = *schar
schar = %x01-2E / %x30-39 / %x3B-5B /%x5D-FF
stream-type = 1*schar
- host-name:
- The host name of a server or the domain name of a domain hosting resource, using the syntax of IPv6address, IPv4address, and reg-name as specified in [RFC3986] ,. The host-name string MUST be a NetBIOS name as specified in [MS-NBTE] section 2.2.1, a fully qualified domain name (FQDN) as specified in [RFC1035] and [RFC1123] , or an IPv4 address as specified in [RFC1123] section 2.1 or an IPv6 address as specified in [RFC4291] section 2.2. share-name: The name of a share or a resource to be accessed. The format of this name depends on the actual file server protocol that is used to access the share. Examples of file server protocols include SMB (as specified in [MS-SMB] ), NFS (as specified in [RFC3530] ), and NCP (as specified in [NOVELL]).
- object-name:
- The name of an object; this name depends on the actual resource accessed. The notation “[object-name]*” indicates that zero or more object names may exist in the path, and each object-name is separated from the immediately preceding object-name with a backslash path separator. In a UNC path used to access files and directories in an SMB share, for example, object-name may be the name of a file or a directory. The host-name, share-name, and object-name are referred to as “pathname components” or “path components”. A valid UNC path consists of two or more path components. The host-name is referred to as the “first pathname component”, the share-name as the “second pathname component”, and so on. The last component of the path is also referred to as the “leaf component”. The protocol that is used to access the resource, and the type of resource that is being accessed, define the size and valid characters for a path component. The only limitations that a Distributed File System (DFS) places on path components are that they MUST be at least one character in length and MUST NOT contain a backslash or null.
- path-name:
- One or more pathname components separated by the “\” backslash character. All pathname components other than the last pathname component denote directories or reparse points.
- file-name:
- The “leaf component” of the path, optionally followed by a ”:” colon character and a stream-name , optionally followed by a ”:” colon character and a stream type. The stream- name, if specified, MAY be zero-length only if stream-type is also specified; otherwise, it MUST be at least one character. The stream-type, if specified, MUST be at least one character.
A short sum-up:
See also
The “file” URI Scheme [RFC8089]
Appendix A.
- UNC Syntax
The UNC filespace selector string is a null-terminated sequence of characters from the Universal Character Set [ISO10646]. The syntax of a UNC filespace selector string, as defined by [MS-DTYP] , is given here in Augmented Backus-Naur Form (ABNF) [RFC5234] for convenience:
UNC = "\\" hostname "\" sharename *( "\" objectname ) hostname = netbios-name / fqdn / ip-address sharename = <name of share or resource to be accessed> objectname = <depends on resource being accessed>
- “netbios-name” from [MS-NBTE], Section 2.2.1.
- “fqdn” from [RFC1035] or [RFC1123]
- “ip-address” from Section 2.1 of [RFC1123], or Section 2.2 of [RFC4291].
The precise format of “sharename” depends on the protocol; see: SMB [MS-SMB] , NFS [RFC3530] , NCP [NOVELL].
DOS/Windows¶
The Windows system adds the following extensions:
drive letters
Universal Naming Convention (UNC) [MS-DTYP]
Namespaces [Win32-Namespaces] prefixed by
- “\\?\” for Win32 File Namespaces
- “\\.\” for Win32 Device Namespaces
- “\\?UNC\” special for “Long UNC”
Note
RFC8089 Appendix-C: This specification does not define a mechanism for translating namespaced paths to or from file URIs.
The filesysobjects support RFC8089 Appendix-D.2 and Appendix-E. E.g.:
file:c:/path/to/file
file:///c:/path/to/file
file:////host.example.com/path/to/file
file://///host.example.com/path/to/file
Note
“E.2.2. Vertical Line Character” is NOT supported.
The splitapppathx disassembles the following parts:
splitapppathx("file:c:/path/to/file") => ('file:', '', 'c:', '/path/to/file')
splitapppathx("file:///c:/path/to/file") => ('file:', '', 'c:', '/path/to/file')
URI/URL/URN¶
The general base specification of a URI/URL/URN is provided by
- Uniform Resource Identifier - URI: Generic Syntax [RFC3986]
See also
- Introduction [RFC3986]
A Uniform Resource Identifier (URI) provides a simple and extensible means for identifying a resource. This specification of URI syntax and semantics is derived from concepts introduced by the World Wide Web global information initiative, whose use of these identifiers dates from 1990 and is described in “Universal Resource Identifiers in WWW” [RFC1630]. The syntax is designed to meet the recommendations laid out in “Functional Recommendations for Internet Resource Locators” [RFC1736] and “Functional Requirements for Uniform Resource Names” [RFC1737].
This document obsoletes [RFC2396], which merged “Uniform Resource Locators” [RFC1738] and “Relative Uniform Resource Locators” [RFC1808] in order to define a single, generic syntax for all URIs. It obsoletes [RFC2732], which introduced syntax for an IPv6 address. It excludes portions of RFC 1738 that defined the specific syntax of individual URI schemes; those portions will be updated as separate documents. The process for registration of new URI schemes is defined separately by [BCP35]. Advice for designers of new URI schemes can be found in [RFC2718]. All significant changes from RFC 2396 are noted in Appendix D.
This specification uses the terms “character” and “coded character set” in accordance with the definitions provided in [BCP19], and “character encoding” in place of what [BCP19] refers to as a “charset”.
See also
1.1. Overview of URIs
URIs are characterized as follows:
Uniform
Uniformity provides several benefits. It allows different types of resource identifiers to be used in the same context, even when the mechanisms used to access those resources may differ. It allows uniform semantic interpretation of common syntactic conventions across different types of resource identifiers. It allows introduction of new types of resource identifiers without interfering with the way that existing identifiers are used. It allows the identifiers to be reused in many different contexts, thus permitting new applications or protocols to leverage a pre existing, large, and widely used set of resource identifiers.
Resource
This specification does not limit the scope of what might be a resource; rather, the term “resource” is used in a general sense for whatever might be identified by a URI. Familiar examples include an electronic document, an image, a source of information with a consistent purpose (e.g., “today’s weather report for Los Angeles”), a service (e.g., an HTTP-to-SMS gateway), and a collection of other resources. A resource is not necessarily accessible via the Internet; e.g., human beings, corporations, and bound books in a library can also be resources. Likewise, abstract concepts can be resources, such as the operators and operands of a mathematical equation, the types of a relationship (e.g., “parent” or “employee”), or numeric values (e.g., zero, one, and infinity).
Identifier
An identifier embodies the information required to distinguish what is being identified from all other things within its scope of identification. Our use of the terms “identify” and “identifying” refer to this purpose of distinguishing one resource from all other resources, regardless of how that purpose is accomplished (e.g., by name, address, or context). These terms should not be mistaken as an assumption that an identifier defines or embodies the identity of what is referenced, though that may be the case for some identifiers. Nor should it be assumed that a system using URIs will access the resource identified: in many cases, URIs are used to denote resources without any intention that they be accessed. Likewise, the “one” resource identified might not be singular in nature (e.g., a resource might be a named set or a mapping that varies over time).
A URI is an identifier consisting of a sequence of characters matching the syntax rule named <URI> in Section 3. It enables uniform identification of resources via a separately defined extensible set of naming schemes (Section 3.1). How that identification is accomplished, assigned, or enabled is delegated to each scheme specification.
This specification does not place any limits on the nature of a resource, the reasons why an application might seek to refer to a resource, or the kinds of systems that might use URIs for the sake of identifying resources. This specification does not require that a URI persists in identifying the same resource over time, though that is a common goal of all URI schemes. Nevertheless, nothing in this specification prevents an application from limiting itself to particular types of resources, or to a subset of URIs that maintains characteristics desired by that application.
URIs have a global scope and are interpreted consistently regardless of context, though the result of that interpretation may be in relation to the end-user’s context. For example, “http://localhost/” has the same interpretation for every user of that reference, even though the network interface corresponding to “localhost” may be different for each end-user: interpretation is independent of access. However, an action made on the basis of that reference will take place in relation to the end-user’s context, which implies that an action intended to refer to a globally unique thing must use a URI that distinguishes that resource from all other things. URIs that identify in relation to the end-user’s local context should only be used when the context itself is a defining aspect of the resource, such as when an on-line help manual refers to a file on the end- user’s file system (e.g., “file:///etc/hosts”).
See also
1.1.3. URI, URL, and URN [RFC3986]
A URI can be further classified as a locator, a name, or both. The term “Uniform Resource Locator” (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism (e.g., its network “location”). The term “Uniform Resource Name” (URN) has been used historically to refer to both URIs under the “urn” scheme [RFC2141], which are required to remain globally unique and persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name.
An individual scheme does not have to be classified as being just one of “name” or “locator”. Instances of URIs from any given scheme may have the characteristics of names or locators or both, often depending on the persistence and care in the assignment of identifiers by the naming authority, rather than on any quality of the scheme. Future specifications and related documentation should use the general term “URI” rather than the more restrictive terms “URL” and “URN” [RFC3305].
For example
See also
1.1.2. Examples [RFC3986]
The following example URIs illustrate several URI schemes and variations in their common syntax components:
ftp://ftp.is.co.za/rfc/rfc1808.txt
http://www.ietf.org/rfc/rfc2396.txt
ldap://[2001:db8::7]/c=GB?objectClass?one
mailto:John.Doe@example.com
news:comp.infosystems.www.servers.unix
tel:+1-816-555-1212
telnet://192.0.2.16:80/
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
Relative URLs are defined in RFC1630 - Universal Resource Identifiers in WWW [RFC1630].
See also
RFC1630 - Universal Resource Identifiers in WWW [RFC1630].
Examples
In the context of URI
magic://a/b/c//d/e/f
the partial URIs would expand as follows:
g magic://a/b/c//d/e/g
/g magic://a/g
//g magic://g
../g magic://a/b/c//d/g
g:h g:h
and in the context of the URI
magic://a/b/c//d/e/
the results would be exactly the same.
The static detection of the represented structure by normapppathx()/normpathx() and though splitapppathx()/splitpathx() for additional ‘padding’ separators is not possible. For example the following normalization:
magic://a//b/c//d///e///// =>??? magic://a/b/c//d/e/
could not safely detect the two relative paths.
The current version supports relative paths literally only by the common flag ‘strip=False‘, which keeps the number of separators ‘/’ untouched. Though the responsibilty for the syntax is passed through to the specific application.
FILE-URI¶
The filesysobjects transparently processes HTTP based file location addresses in accordance to:
- Uniform Resource Locators (URL) [RFC1738],
- Uniform Resource Identifiers (URI): Generic Syntax [RFC2396]
- A URN Namespace for IETF Documents [RFC2648]
- Uniform Resource Identifier - URI: Generic Syntax [RFC3986]
- The file URI Scheme - draft-kerwin-file-scheme-13; IETF [URISCHEME] / current [RFC8089]
- The “file” URI Scheme - 2017 [RFC8089]
The implemented URI/URL is decribed in detail by The “file” URI Scheme [RFC8089]
Syntax¶
The lates standard is [RFC8089]
See also
The “file” URI Scheme [RFC8089]
file-URI = file-scheme ":" file-hier-part
file-scheme = "file"
file-hier-part = ( "//" auth-path )
/ local-path
auth-path = [ file-auth ] path-absolute
local-path = path-absolute
file-auth = "localhost"
/ host
Extended with UNC paths, see RFC8089 - E.3.2. <file> URI with UNC Path”.
To interpret such URIs, the "auth-path" rule in Section 2 can be
replaced with the following:
auth-path = [ file-auth ] path-absolute
/ unc-authority path-absolute
unc-authority = 2*3"/" file-host
file-host = inline-IP / IPv4address / reg-name
inline-IP = "%5B" ( IPv6address / IPvFuture ) "%5D"
The path-absolute definition:
See also
The “file” URI Scheme [RFC3986]
path = path-abempty ; begins with "/" or is empty
/ path-absolute ; begins with "/" but not "//"
/ path-noscheme ; begins with a non-colon segment
/ path-rootless ; begins with a segment
/ path-empty ; zero characters
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-noscheme = segment-nz-nc *( "/" segment )
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
segment = *pchar
segment-nz = 1*pchar
segment-nz-nc = 1*( unreserved / pct-encoded / sub-delims / "@" )
; non-zero-length segment without any colon ":"
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
pct-encoded = "%" HEXDIG HEXDIG
sub-delims = "!" / "$" / "&" / "’" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
The supported RFC8089 results into the following URIs:
file-URI = scheme + authority + path
file-URI(local-short) = "file:" path-absolute
file-URI(local) = "file://" path-absolute
file-URI(local) = "file://" "localhost" path-absolute
file-URI(remote) = "file://" host path-absolute
file-URI(unc) = "file:////" host path-absolute
file-URI(unc) = "file://///" host path-absolute
With the special cases as described in “RFC8089 - Appendix E. Nonstandard Syntax Variations”.
Definitions by RFC8089¶
The following table lists the supported syntax variants by filesysobjects.
| document | reference | pg. | File-uri | Alternatives-posix | Alternatives-win |
|---|---|---|---|---|---|
| RFC8089 |
|
3 | all | all | all |
| RFC8089 | Annex B | 10 | file:///path/to/file | /path/to/file | \path\to\file |
| RFC8089 | Annex B | 10 | file:/path/to/file | /path/to/file | \path\to\file |
| RFC8089 | Annex B | 10 | file://host.example.com/path/to/file | host.example.com:/path/to/file | \path\to\file |
| RFC8089 | Appendix E.2 | 13 | file:c:/path/to/file | c:/path/to/file | c:\path\to\file |
| RFC8089 | Appendix E.2 | 13 | file:///c:/path/to/file | c:/path/to/file | c:\path\to\file |
| RFC8089 | Appendix E.3.1 | 15 | file://host.example.com/Share/path/to/file.txt | //host.example.com/Share/path/to/file.txt | \\host.example.com\path\to\file |
| RFC8089 | Appendix E.3.2 | 16 | file:////host.example.com/path/to/file | //host.example.com/path/to/file | \path\to\file |
| RFC8089 | Appendix E.3.2 | 16 | file://///host.example.com/path/to/file | //host.example.com/path/to/file | \\host.example.com\path\to\file |
| RFC8089 | Appendix F | 17 | file:///path/to/file | /path/to/file | \path\to\file |
| RFC8089 | Appendix F | 17 | file:/path/to/file | /path/to/file | \path\to\file |
| RFC8089 | Appendix F | 18 | file:c:/path/to/file | c:/path/to/file | c:\path\to\file |
| RFC8089 | Appendix F | 18 | file://host.example.com/path/to/file | //host.example.com/path/to/file | \\host.example.com\path\to\file |
| RFC8089 | Appendix F | 18 | file:////host.example.com/path/to/file | //host.example.com/path/to/file | \\host.example.com\path\to\file |
| RFC8089 | Appendix F | 18 | file://///host.example.com/path/to/file | //host.example.com/path/to/file | \\host.example.com\path\to\file |
The support includes the conversion of mixed separators, cross-conversion, forward and revers conversion of path-items, search paths, and URI syntax. E.g.
file:///path\to/file => /path/to/file
file://\\path/to\file => //path/to/file or \\path\to\file
HTTP/HTTPS¶
Syntax¶
The syntax for a URI as defined by the RFC is
See also
Appendix A. Collected ABNF for URI [RFC3986]:
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
hier-part = "//" authority path-abempty
/ path-absolute
/ path-rootless
/ path-empty
URI-reference = URI / relative-ref
absolute-URI = scheme ":" hier-part [ "?" query ]
relative-ref = relative-part [ "?" query ] [ "#" fragment ]
relative-part = "//" authority path-abempty
/ path-absolute
/ path-noscheme
/ path-empty
scheme = ALPHA *( ALPHA / DIGIT / "+" / "-" / "." )
authority = [ userinfo "@" ] host [ ":" port ]
userinfo = *( unreserved / pct-encoded / sub-delims / ":" )
host = IP-literal / IPv4address / reg-name
port = *DIGIT
IP-literal = "[" ( IPv6address / IPvFuture
IPvFuture = "v" 1*HEXDIG "." 1*( unreserved / sub-delims / ":" )
IPv6address = 6( h16 ":" ) ls32
/ "::" 5( h16 ":" ) ls32
/ [ h16 ] "::" 4( h16 ":" ) ls32
/ [ *1( h16 ":" ) h16 ] "::" 3( h16 ":" ) ls32
/ [ *2( h16 ":" ) h16 ] "::" 2( h16 ":" ) ls32
/ [ *3( h16 ":" ) h16 ] "::" h16 ":" ls32
/ [ *4( h16 ":" ) h16 ] "::" ls32
/ [ *5( h16 ":" ) h16 ] "::" h16
/ [ *6( h16 ":" ) h16 ] "::"
h16 = 1*4HEXDIG
ls32 = ( h16 ":" h16 ) / IPv4address
IPv4address = dec-octet "." dec-octet "." dec-octet "." dec-octet
dec-octet = DIGIT ; 0-9
/ %x31-39 DIGIT ; 10-99
/ "1" 2DIGIT ; 100-199
/ "2" %x30-34 DIGIT ; 200-249
/ "25" %x30-35 ; 250-255
reg-name = *( unreserved / pct-encoded / sub-delims )
path = path-abempty ; begins with "/" or is empty
/ path-absolute ; begins with "/" but not "//"
/ path-noscheme ; begins with a non-colon segment
/ path-rootless ; begins with a segment
/ path-empty ; zero characters
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-noscheme = segment-nz-nc *( "/" segment )
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
segment = *pchar
segment-nz = 1*pchar
segment-nz-nc = 1*( unreserved / pct-encoded / sub-delims / "@" )
; non-zero-length segment without any colon ":"
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
query = *( pchar / "/" / "?" )
fragment = *( pchar / "/" / "?" )
pct-encoded = "%" HEXDIG HEXDIG
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "’" / "(" / ")"
/ "*" / "+" / "," / ";" / "="
Thus for example the existing and functioning URL - at the time of writing - is not valid in accordance to RFC3986:
https://bazaar.launchpad.net/~jakob-simon-gaarde/ladon/trunk/files/head:/frameworks/python/
This is because the path segment ‘head:’ contains a colon, while this is a reserved character, and though excluded from the use witin a segment. Therefore the filesysobjects standard procedure splitapppathx() fails to handle this URL, which is detected in URL/POSIX mode as two separate path entries due to the ambiguity of the path separator ‘:’.
[
('https', 'bazaar.launchpad.net', '/~jakob-simon-gaarde/ladon/trunk/files/head', ''),
('lfsys', '', '', '/frameworks/python')
]
The current version supports the following workarounds:
cgi-representation:
The representation for ‘:’ is ‘%3a’, which does not need to be unquoted.
.../head%3a/....
quotes:
The quoted parts are kept literally and could be un-quoted when required.
.../"""head:"""/.... .../'''head:'''/....
This preserves the colon and keeps the path as one. While the application knows what to do and can unquote as required.
SMB¶
The Server name resolution of the Message Block (SMB) Protocol [MS-SMB] is currently implemented as a limited version of the file scheme. Thus based on “SMB File Sharing URI Scheme - draft-crhertel-smb-url-07”. This is outdated, but for now the first attempt for start.
Syntax¶
The latest standard is [MS-SMB2] [MS-SMB]
See also
Message Block (SMB) Protocol [MS-SMB]
smb_URI = ( smb_absURI | smb_relURI )
smb_absURI = scheme "://" smb_service [ "?" [ nbt_context ] ]
smb_relURI = abs_path | rel_path
scheme = "smb" | "cifs"
smb_service = ( smb_browse | smb_net_path )
smb_browse = [ smb_userinfo "@" ] [ smb_srv_name ]
[ ":" port ] [ "/" ]
smb_net_path = smb_server [ abs_path ]
smb_server = [ smb_userinfo "@" ] smb_srv_name [ ":" port ]
smb_srv_name = nbt_name | host
nbt_name = netbiosname [ "." scope_id ]
netbiosname = 1*( netbiosnamec ) *( netbiosnamec | "*" )
netbiosnamec = ( alphanum | escaped | ":" | "=" | "+" | "$" |
"," | "-" | "_" | "!" | "~" | "'" | "(" | ")" )
scope_id = domainlabel *( "." domainlabel )
smb_userinfo = [ auth_domain ";" ] userinfo_nosem
auth_domain = smb_srv_name
userinfo_nosem = *( unreserved | escaped |
":" | "&" | "=" | "+" | "$" | "," )
nbt_context = nbt_param *(";" nbt_param )
nbt_param = ( "BROADCAST=" IPv4address [ ":" port ]
| "CALLED=" netbiosname
| "CALLING=" netbiosname
| ( "NBNS=" | "WINS=" ) host [ ":" port ]
| "NODETYPE=" ("B" | "P" | "M" | "H")
| ( "SCOPEID=" | "SCOPE=" ) scope_id
)
Resources¶
The supported standards in accordance to [POSIX]/[IEEE], [IETF], and filesystem conventions [MSDN] and [MSOSPEC] are:
- [CIFS]: Common Internet File System
- [CYGWIN]: Cygwin
- [IEEE1003C412]: IEEE Std 1003.1(TM), 2013 Edition; Chapter 4.12
- [IEEE1003]: IEEE Std 1003.1(TM), 2013 Edition
- [ISSUE26329]: Python - Issue 26329: os.path.normpath(“//”) returns //
- [MS-CIFS]: Common Internet File System (CIFS) Protocol; Microsoft Inc.
- [MS-DTYP]: Windows Data Types - Chap. 2.2.57 UNC; Microsoft Inc.
- [MS-FSCC]: File System Control Codes
- [MS-SMB]: Server Message Block (SMB) Protocol; Microsoft Inc.
- [MSOSPEC] Open Specifications
- [pathlib] lib/pathlib - Python3
- [POSIX]: IEEE Std 1003.1(TM), 2013 Edition
- [RFC1035]: DOMAIN NAMES - IMPLEMENTATION AND SPECIFICATION
- [RFC1630]: Universal Resource Identifiers in WWW
- [RFC1123]: Requirements for Internet Hosts – Application and Support
- [RFC1738]: Uniform Resource Locators (URL)
- [RFC1808]: Relative Uniform Resource Locators
- [RFC2141]: URN Syntax
- [RFC2279]: UTF-8, a transformation format of ISO 10646
- [RFC2396]: Uniform Resource Identifiers (URI): Generic Syntax
- [RFC2648]: A URN Namespace for IETF Documents
- [RFC3061]: A URN Namespace of Object Identifiers
- [RFC3305]: Uniform Resource Identifiers (URIs), URLs, and Uniform Resource Names (URNs): Clarifications and Recommendations;
- [RFC3492]: Punycode: A Bootstring encoding of Unicode for Internationalized Domain Names in Applications (IDNA)
- [RFC3530]: Network File System (NFS) version 4 Protocol;
- [RFC3986]: Uniform Resource Identifier - URI: Generic Syntax
- [RFC3987]: Internationalized Resource Identifiers (IRIs)
- [RFC4088]: Uniform Resource Identifier (URI) Scheme for the Simple Network Management Protocol (SNMP)
- [RFC4122]: A Universally Unique IDentifier (UUID) URN Namespace
- [RFC4291]: IP Version 6 Addressing Architecture
- [RFC5234]: URIRFC 5234 - Augmented BNF for Syntax Specifications: ABNF
- [RFC6570]: URI Template
- [RFC7320]: URI Design and Ownership
- [RFC8089]: The “file” URI Scheme
- [SAMBA]: Samba - opening windows to a wider world
- [SMBCIFS]: Microsoft SMB Protocol and CIFS Protocol
- [SMBURI]: SMB File Sharing URI Scheme - outdated
- [UNC]: UNC: Common definition in [MS-DTYP]: Windows Data Types - Chap. 2.2.57 UNC; Microsoft Inc.
- [URISCHEME]: The file URI Scheme - draft-kerwin-file-scheme-13; IETF
- [URLPARSING]: Living Standard — Last Updated 27 November 2017 - 4.4. URL parsing
- [URLVALIDATOR]: W3C Link Checker
- [macpath]: legacy lib/macpath - macpath() variants
- [normpath]: lib/os.path - os.path.normpath()
- [os.path]: lib/os.path - os.path.normpath() variants
- updates and and additional others...
